
sklearn机器学习入门及其模型参数讲解
数据集介绍及数据处理
-
sklearn数据集
名称 调用 适用 规模 波士顿房价数据集 load_boston() 回归 506*13 鸢尾花数据集 load_iris() 分类 150*4 糖尿病数据集 load_diabetes() 回归 442*10 手写数字数据集 load_digits() 分类 5620*64 Olivetti脸部图像数据集 fetch_olivetti_faces() 降维 400 64 64 新闻分类数据集 fetch_20newsgroups() 分类 --- 带标签的人脸数据集 fetch_lfw_people() 分类/降维 --- 路透社新闻语料数据集 fetch_rcv1() 分类 804414* 47236 其中前四项为
小数据集,后四项为大数据集 -
sklearn.datasets( 1 )datasets.load_*()
获取小规模数据集,数据包含在datasets里
( 2 )datasets.fetch_*()
获取大规模莫数据集,需要从网上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/,要修改默认目录,可以修改环境变量SCIKIT_LEARN_DATA
( 3 )datasets.make_*()
从本地生成数据集
load*和fetch*函数返回的数据类型是datasets.base.Bunch,本质上是一个 dict,它的键值对可用通过对象的属性方式访问。主要包含以下属性:**data:特征数据数组,是 n_samples * n_features 的二维 numpy.ndarray 数组target:标签数组,是 n_samples 的一维 numpy.ndarray 数组DESCR:数据描述feature_names:特征名target_names:标签名
数据集目录可以通过
datasets.get_data_home()获取,clear_data_home(data_home=None)删除所有下载数据 -
datasets.get_data_home(data_home=None)返回scikit学习数据目录的路径。这个文件夹被一些大的数据集装载器使用,以避免下载数据。默认情况下,数据目录设置为用户主文件夹中名为
scikit_learn_data的文件夹。或者,可以通过SCIKIT_LEARN_DATA环境变量或通过给出显式的文件夹路径以编程方式设置它。〜符号扩展到用户主文件夹。如果文件夹不存在,则会自动创建。 -
**sklearn.datasets.clear_data_home(data_home=None)**删除存储目录中的数据
获取小数据集
用于分类
-
sklearn.datasets.load_iris
鸢尾花数据集采集的是鸢尾花的测量数据以及其所属的类别。测量数据包括:萼片长度、萼片宽度、花瓣长度、花瓣宽度。类别共分为三类:
Iris Setosa,Iris Versicolour,Iris Virginica。该数据集可用于多分类问题。加载数据集参数有
return_X_y:若为True,则以(data, target)元组形式返回数据;默认为False,表示以字典形 式返回数据全部信息(包括data和target)。
from sklearn.datasets import load_iris
data=load_iris(return_X_y=True)
data = load_iris()
# 查看data所具有的属性或方法
print(dir(data))
# 查看数据集的描述
print(data.DESCR)
# 查看数据的特征名
print(data.feature_names)
# 查看数据的分类名
print(data.target_names)
print(data.target)
# 查看第2、11、101个样本的目标值
print(data.target[[1, 10, 100]])- sklearn.datasets.load_digits
手写数字数据集包括1797个0-9的手写数字数据,每个数字由8*8大小的矩阵构成,矩阵中值的范围是0-16,代表颜色的深度
- 加载数据集其参数包括:
• return_X_y:若为True,则以(data, target)形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target) ;
• n_class:表示返回数据的类别数,默认= 10,如:n_class=5,则返回0到4的数据样本。
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
digits = load_digits(n_class=10, return_X_y=False)
# 查看第1-10个样本的目标值
print(digits.target[0:10])
print(dir(digits))
print(digits.DESCR)
print(digits.data)
print(digits.target_names)
print(digits.target[[2, 20, 200]])
print(digits.images.shape)
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.matshow(digits.images[1])
plt.title('手写数字1')
plt.savefig('手写数字1')
plt.show()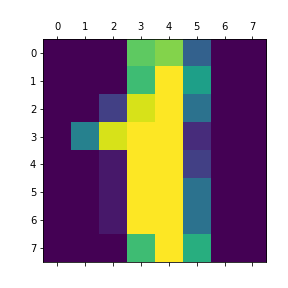
用于回归
-
sklearn.datasets.load_boston
波士顿房价数据集包含506组数据,每条数据包含房屋以及房屋周围的详细信息。其中包括城镇犯罪率、一氧化氮浓度、住宅平均房间数、到中心区域的加权距离以及自住房平均房价等。
-
波士顿房价数据集属性描述
CRIM:城镇人均犯罪率。
ZN:住宅用地超过 25000 sq.ft. 的比例。
INDUS:城镇非零售商用土地的比例。
CHAS:查理斯河空变量(如果边界是河流,则为1;否则为0)
NOX:一氧化氮浓度。
RM:住宅平均房间数。
AGE:1940 年之前建成的自用房屋比例。
DIS:到波士顿五个中心区域的加权距离。
RAD:辐射性公路的接近指数。
TAX:每 10000 美元的全值财产税率。
PTRATIO:城镇师生比例。
B:1000(Bk-0.63)^ 2,其中 Bk 指代城镇中黑人的比例。
LSTAT:人口中地位低下者的比例。
MEDV:自住房的平均房价,以千美元计。 -
加载数据集其参数有:
• return_X_y:若为True,则以(data, target)元组形式返回数据;默认为False,表示以字典形式返回数据全部信息(包括data和target)。
from sklearn.datasets import load_boston
boston = load_boston()
print(dir(boston))
print('*'*80)
print(boston.DESCR)
print('*'*80)
print(boston.feature_names)
print(boston.data)
print('*'*80)
print(boston.filename)
print('*'*80)
print(boston.target)获取大数据集
-
sklearn.datasets.fetch_20newsgroups
-
加载数据集其参数有:
subset: ‘train’或者’test’,‘all’,可选,选择要加载的数据集:训练集的“训练”,测试集的“测试”,两者的“全部”
data_home: 可选,默认值:无。指定数据集的下载路径。如果没有,所有scikit学习数据都存储在’〜/ scikit_learn_data’子文件夹中
categories: 选取哪一类数据集[类别列表],默认20类
shuffle: 是否对数据进行随机排序
random_state: numpy随机数生成器或种子整数
download_if_missing: 可选,默认为True,如果没有下载过,重新下载
remove: (‘headers’,‘footers’,‘quotes’)删除部分文本
from sklearn.datasets import fetch_20newsgroups
data_test = fetch_20newsgroups(subset='test',shuffle=True,random_state=42)
data_train = fetch_20newsgroups(subset='train',shuffle=True,random_state=42)
print(dir(data_train))
print('*'*80)
#print(data_train.DESCR)
print('*'*80)
print(data_test.data[0]) #测试集中的第一篇文档
print('-'*80)
print('训练集数据分类名称:{} '.format(data_train.target_names))
print(data_test.target[:10])
print('*'*80)
print('训练集数据:{} 条'.format(data_train.target.shape))
print('测试集数据:{} 条'.format(data_test.target.shape))-
sklearn.datasets.fetch_20newsgroups_vectorized
加载20个新闻组数据集并将其转换为tf-idf向量,这是一个方便的功能; 使用
sklearn.feature_ extraction.text.Vectorizer的默认设置完成tf-idf 转换。
from sklearn.datasets import fetch_20newsgroups_vectorized
from sklearn.utils import shuffle
bunch = fetch_20newsgroups_vectorized(subset='all')
X,y = shuffle(bunch.data,bunch.target)
print(X.shape)
# 数据集划分为训练集0.7和测试集0.3
offset = int(X.shape[0]*0.7)
X_train, y_train = X[0:offset], y[0:offset]
X_test, y_test = X[offset:], y[offset:]
print(X_train.shape)
print(X_test.shape)获取本地生成数据
生成本地分类数据:
-
sklearn.datasets.make_classification
-
加载数据集其参数有:
n_samples:int,optional(default = 100),样本数量
n_features:int,可选(默认= 20),特征总数= n_informative + n_redundant + n_repeated
n_informative:多信息特征的个数
n_redundant:冗余信息,informative特征的随机线性组合
n_repeated :重复信息,随机提取n_informative和n_redundant 特征
n_classes:int,可选(default = 2),分类类别
n_clusters_per_class :某一个类别是由几个cluster构成的
random_state:int,RandomState实例,可选(默认=无)如果int,random_state是随机数生成器使用的种子
from sklearn import datasets import matplotlib.pyplot as plt data,target = datasets.make_classification(n_samples=100,n_features=2, n_informative=2,n_redundant=0,n_repeated=0, n_classes=2,n_clusters_per_class=1, random_state=0) print(data.shape) print(target.shape) #print(data) #print(target) plt.scatter(data[:,0],data[:,1],c=target) plt.show()
生成本地回归数据:
-
sklearn.datasets.make_regression
-
加载数据集其参数有:
n_samples: int,optional(default = 100),样本数量
n_features: int,optional(default = 100),特征数量
coef: boolean,optional(default = False),如果为True,则返回底层线性模型的系数
random_state: int,RandomState实例,可选(默认=无)
from sklearn.datasets.samples_generator import make_regression X, y = make_regression(n_samples=100, n_features=10, random_state=1) print(X.shape) print(y.shape)
图像数据
在Anaconda中sklearn中的图像在该目录下
D:\Anaconda3\Lib\site-packages\sklearn\datasets\images
存在china.jpg和flower.jpg
from sklearn.datasets import load_sample_image
import matplotlib.pyplot as plt
img = load_sample_image('china.jpg')
plt.imshow(img)
模型的定义
在这一步我们首先要分析自己数据的类型,搞清出你要用什么模型来做,然后我们就可以在sklearn中定义模型了。sklearn为所有模型提供了非常相似的接口,这样使得我们可以更加快速的熟悉所有模型的用法。在这之前我们先来看看模型的常用属性和功能:
# 拟合模型
model.fit(X_train, y_train)
# 模型预测
model.predict(X_test)
# 获得这个模型的参数
model.get_params()
# 为模型进行打分
model.score(data_X, data_y) # 线性回归:R square; 分类问题: acc1. 线性回归
from sklearn.linear_model import LinearRegression
# 定义线性回归模型
model = LinearRegression(fit_intercept=True, normalize=False,
copy_X=True, n_jobs=1)
"""
参数
---
fit_intercept:是否计算截距。False-模型没有截距
normalize: 当fit_intercept设置为False时,该参数将被忽略。 如果为真,则回归前的回归系数X将通过减去平均值并除以l2-范数而归一化。
n_jobs:指定线程数
"""

2. 逻辑回归LR
from sklearn.linear_model import LogisticRegression
# 定义逻辑回归模型
model = LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver=’liblinear’, max_iter=100, multi_class=’ovr’,
verbose=0, warm_start=False, n_jobs=1)
"""参数
---
penalty:使用指定正则化项(默认:l2)
dual: n_samples > n_features取False(默认)
C:正则化强度的反,值越小正则化强度越大
n_jobs: 指定线程数
random_state:随机数生成器
fit_intercept: 是否需要常量
"""3. 朴素贝叶斯算法NB
from sklearn import naive_bayes
model = naive_bayes.GaussianNB() # 高斯贝叶斯
model = naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
model = naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)
"""
文本分类问题常用MultinomialNB
参数
---
alpha:平滑参数
fit_prior:是否要学习类的先验概率;false-使用统一的先验概率
class_prior: 是否指定类的先验概率;若指定则不能根据参数调整
binarize: 二值化的阈值,若为None,则假设输入由二进制向量组成4. 决策树DT
from sklearn import tree
model = tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=None, random_state=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
class_weight=None, presort=False)
"""参数
---
criterion :特征选择准则gini/entropy
max_depth:树的最大深度,None-尽量下分
min_samples_split:分裂内部节点,所需要的最小样本树
min_samples_leaf:叶子节点所需要的最小样本数
max_features: 寻找最优分割点时的最大特征数
max_leaf_nodes:优先增长到最大叶子节点数
min_impurity_decrease:如果这种分离导致杂质的减少大于或等于这个值,则节点将被拆分。
"""5. 支持向量机SVM
from sklearn.svm import SVC
model = SVC(C=1.0, kernel=’rbf’, gamma=’auto’)
"""参数
---
C:误差项的惩罚参数C
gamma: 核相关系数。浮点数,If gamma is ‘auto’ then 1/n_features will be used instead.
"""6. k近邻算法KNN
from sklearn import neighbors
#定义kNN分类模型
model = neighbors.KNeighborsClassifier(n_neighbors=5, n_jobs=1) # 分类
model = neighbors.KNeighborsRegressor(n_neighbors=5, n_jobs=1) # 回归
"""参数
---
n_neighbors: 使用邻居的数目
n_jobs:并行任务数
"""7. 多层感知机(神经网络)
from sklearn.neural_network import MLPClassifier
# 定义多层感知机分类算法
model = MLPClassifier(activation='relu', solver='adam', alpha=0.0001)
"""参数
---
hidden_layer_sizes: 元祖
activation:激活函数
solver :优化算法{‘lbfgs’, ‘sgd’, ‘adam’}
alpha:L2惩罚(正则化项)参数。
"""模型评分
有三种不同的方法来评估一个模型的预测质量:
- estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题。
- Scoring参数:使用cross-validation的模型评估工具,依赖于内部的scoring策略。见下。
- 通过测试集上评估预测误差:sklearn Metric函数用来评估预测误差。
评价指标
评价指标针对不同的机器学习任务有不同的指标,同一任务也有不同侧重点的评价指标。
主要有分类(classification)、回归(regression)、排序(ranking)、聚类(clustering)、热门主题模型(topic modeling)、推荐(recommendation)等。
1.分类评价指标
acc、recall、F1、混淆矩阵、分类综合报告
1.准确率
方式一:accuracy_score
# 准确率
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3,9,9,8,5,8]
y_true = [0, 1, 2, 3,2,6,3,5,9]
accuracy_score(y_true, y_pred)
Out[127]: 0.33333333333333331
accuracy_score(y_true, y_pred, normalize=False) # 类似海明距离,每个类别求准确后,再求微平均
Out[128]: 3
123456789101112方式二:metrics
宏平均比微平均更合理,但也不是说微平均一无是处,具体使用哪种评测机制,还是要取决于数据集中样本分布
宏平均(Macro-averaging),是先对每一个类统计指标值,然后在对所有类求算术平均值。
微平均(Micro-averaging),是对数据集中的每一个实例不分类别进行统计建立全局混淆矩阵,然后计算相应指标。参考博客
from sklearn import metrics
metrics.precision_score(y_true, y_pred, average='micro') # 微平均,精确率
Out[130]: 0.33333333333333331
metrics.precision_score(y_true, y_pred, average='macro') # 宏平均,精确率
Out[131]: 0.375
metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro') # 指定特定分类标签的精确率
Out[133]: 0.5
12345678910其中average参数有五种:(None, ‘micro’, ‘macro’, ‘weighted’, ‘samples’)
2.召回率
metrics.recall_score(y_true, y_pred, average='micro')
Out[134]: 0.33333333333333331
metrics.recall_score(y_true, y_pred, average='macro')
Out[135]: 0.3125
1234563.F1分数
metrics.f1_score(y_true, y_pred, average='weighted')
Out[136]: 0.37037037037037035
124.混淆矩阵
# 混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
Out[137]:
array([[1, 0, 0, ..., 0, 0, 0],
[0, 0, 1, ..., 0, 0, 0],
[0, 1, 0, ..., 0, 0, 1],
...,
[0, 0, 0, ..., 0, 0, 1],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 1, 0]])
12345678910111213横为true label 竖为predict

5.分类报告
# 分类报告:precision/recall/fi-score/均值/分类个数
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 2, 0]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
123456包含:precision/recall/fi-score/均值/分类个数
6.kappa score
kappa score是一个介于(-1, 1)之间的数. score>0.8意味着好的分类;0或更低意味着不好(实际是随机标签)
from sklearn.metrics import cohen_kappa_score
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
cohen_kappa_score(y_true, y_pred)
1234ROC
1.ROC计算
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
123452.ROC曲线
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2)
1233.具体实例
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from scipy import interp
# Import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 画图
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves
plt.figure()
plt.plot(fpr["micro"], tpr["micro"],
label='micro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["micro"]),
color='deeppink', linestyle=':', linewidth=4)
plt.plot(fpr["macro"], tpr["macro"],
label='macro-average ROC curve (area = {0:0.2f})'
''.format(roc_auc["macro"]),
color='navy', linestyle=':', linewidth=4)
colors = cycle(['aqua', 'darkorange', 'cornflowerblue'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=lw,
label='ROC curve of class {0} (area = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Some extension of Receiver operating characteristic to multi-class')
plt.legend(loc="lower right")
plt.show()
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657
2.回归评价指标
回归是对连续的实数值进行预测,而分类中是离散值。



3.聚类评价指标
1.Adjusted Rand index 调整兰德系数

>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_rand_score(labels_true, labels_pred)
12345672.Mutual Information based scores 互信息

>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.adjusted_mutual_info_score(labels_true, labels_pred)
0.22504
12345673.Homogeneity, completeness and V-measure
同质性homogeneity:每个群集只包含单个类的成员。
完整性completeness:给定类的所有成员都分配给同一个群集。
>>> from sklearn import metrics
>>> labels_true = [0, 0, 0, 1, 1, 1]
>>> labels_pred = [0, 0, 1, 1, 2, 2]
>>> metrics.homogeneity_score(labels_true, labels_pred)
0.66...
>>> metrics.completeness_score(labels_true, labels_pred)
12345678910
4.Fowlkes-Mallows scores

5.Silhouette Coefficient 轮廓系数

6.Calinski-Harabaz Index

模型保存
最后,我们可以将我们训练好的model保存到本地,或者放到线上供用户使用,那么如何保存训练好的model呢?主要有下面两种方式:
1. 保存为pickle文件
import pickle
# 保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 读取模型
with open('model.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_test)2. 保存为pickle文件
from sklearn.externals import joblib
# 保存模型
joblib.dump(model, 'model.pickle')
#载入模型
model = joblib.load('model.pickle')








